| Pages in topic: [1 2 3] > |
How to convert TMX to tab-delimited? Thread poster: Hans Lenting
|
|---|
I am looking for an easy way to convert TMX files (~100 MB) to tab-delimited files?
I tried WfConverter but it doesn't remove the invalid characters that are present in the TMX (created with WfConverter itself). Some superfluous columns are added.
I think that the files are too huge for Goldpan, at least it becomes very unresponsive.
Next option: Xbench 2.9. The conversion is okay, but some superfluous columns are added.

What are the other options?
| | | |
Andriy Yasharov 
Ukraine
Local time: 17:15
Member (2008)
English to Russian
+ ...
| Heartsome TMX Editor 8 | Oct 13, 2022 |
Perhaps Heartsome TMX Editor 8 may help. It can convert tmx files to tabbed txt files.
Download links are:
... See more
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | Not on macOS Big Sur | Oct 13, 2022 |
Andriy Yasharov wrote:
Perhaps Heartsome TMX Editor 8 may help. It can convert tmx files to tabbed txt files.
Thanks, but it doesn't work on macOS Big Sur. I don't have permission to open the app. There are hacks, but I don't want to go that way.
| | | |
Samuel Murray
Netherlands
Local time: 16:15
Member (2006)
English to Afrikaans
+ ...
How many columns do you want (i.e. what do you want in those columns)?
| | |
|
|
|
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | Only source and target | Oct 13, 2022 |
Only source and target, nothing more.
| | | |
Samuel Murray
Netherlands
Local time: 16:15
Member (2006)
English to Afrikaans
+ ...
Hans Lenting wrote:
I tried WfConverter but it doesn't remove the invalid characters that are present in the TMX (created with WfConverter itself).
Are you sure those characters were put there by the converter? Could they possibly be present in the TMX file? I have a small AutoIt script that attempts to remove a couple of characters from TMX files and escape unrecognized entities in the TMX file here. Removing those characters and/or escaping unknown entities may help the file get converted better. The script [tmxfixerbasic_noisy (utf16le).au3] takes about 20 seconds to process a 200 MB TMX file.
Next option: Xbench 2.9. The conversion is okay...
I thought Xbench 2.9 can't handle Unicode correctly...?
Disfr takes 30 seconds to convert a 200 MB TMX file to Excel:
https://github.com/AlissaSabre/disfr
though unfortunately all tags are converted to {ph}.
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | In the sdlmb | Oct 13, 2022 |
Samuel Murray wrote:
Hans Lenting wrote:
I tried WfConverter but it doesn't remove the invalid characters that are present in the TMX (created with WfConverter itself).
Are you sure those characters were put there by the converter?
No they are already in the sdlmb files.
I can do Find and Replace actions with BBEdit. This editor also offers a ZAP Gremlins command. But äß etc. are zapped too. Those Americans stick to their lower ASCII . I've contacted their support. . I've contacted their support.
Thanks for your kind offer. For now I'll try to find my own solution.
| | | |
Samuel Murray
Netherlands
Local time: 16:15
Member (2006)
English to Afrikaans
+ ...
Hans Lenting wrote:
No they are already in the SDLMB files.
Do you mean SDLTM files? Aaah, you're converting Trados memories to TMX and then to tabbed files, is that so?
I can do Find and Replace actions with BBEdit. This editor also offers a ZAP Gremlins command.
The gremlins that my script removes are:
- [\x00-\x08]|\x0B|\x0C|[\x0E-\x1F] (characters that are not valid XML)
- Any entity that's not LT, GT, AMP, APOS or QUOT
| | |
|
|
|
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER
Reply from them:
Thanks for your reply and given this additional info, you'll probably be better off using a character set range (or several ranges) to match the unwanted characters, whether via the Replace All command or a set of Replace All actions within a _text factory_.
For example, please try performing a Replace All with the following pattern:
Find: [\x{0100}-\x{FFFF}]
and with the "Grep" and "Case sensitive" options enabled, on a cop... See more Reply from them:
Thanks for your reply and given this additional info, you'll probably be better off using a character set range (or several ranges) to match the unwanted characters, whether via the Replace All command or a set of Replace All actions within a _text factory_.
For example, please try performing a Replace All with the following pattern:
Find: [\x{0100}-\x{FFFF}]
and with the "Grep" and "Case sensitive" options enabled, on a copy of any file whose contents you need to clean up.
(Note: This pattern starts matching at the beginning of the "Latin Extended-A" range and continued through to the end of the "Specials" range.)
EDIT: The given range actually doesn't work.
[Edited at 2022-10-14 08:05 GMT] ▲ Collapse
| | | |
Stepan Konev
Russian Federation
Local time: 18:15
English to Russian
| A text editor that supports regular expressions | Oct 14, 2022 |
If I had to do this task, I would use a text editor that supports regex (similar to Notepad++, for MacOS).
If that MacOS text editor can mark the match, you can use the following regex:
(?<=<seg>)(\n|.)*?(?=</seg>)
to mark and then copy all segments to clipboard:

Then you paste the copied segments into an MS Word file and convert it a... See more If I had to do this task, I would use a text editor that supports regex (similar to Notepad++, for MacOS).
If that MacOS text editor can mark the match, you can use the following regex:
(?<=<seg>)(\n|.)*?(?=</seg>)
to mark and then copy all segments to clipboard:
Then you paste the copied segments into an MS Word file and convert it all into a 2-column table.
If there is no text editor available for MacOS that can mark and copy the marked text to clipboard, then you have to use an inverted regex for replacement:
^(.(?!(<seg>(\n|.)+?</seg>)))*$
to replace the match with a blank field.

Then you can copy it all into MS Word and remove blank strings by replacing two paragraph marks with one. And again select all and convert into a 2-column table.
[Edited at 2022-10-14 01:06 GMT] ▲ Collapse
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER
That is a very nice procedure, Stepan!
Stepan Konev wrote:
If I had to do this task, I would use a text editor that supports regex (similar to Notepad++, for MacOS).
...
Then you paste the copied segments into an MS Word file and convert it all into a 2-column table.
BBEdit is certainly capable of extracting the contents of the segments via a regular expression. Thanks for the idea!
However, I find that Ms Word gets slow when converting hundreds of thousands of lines to a table. So I created two additional regular expressions to get rid of the source segment identifier and replace the target segment identifier with at tab character.

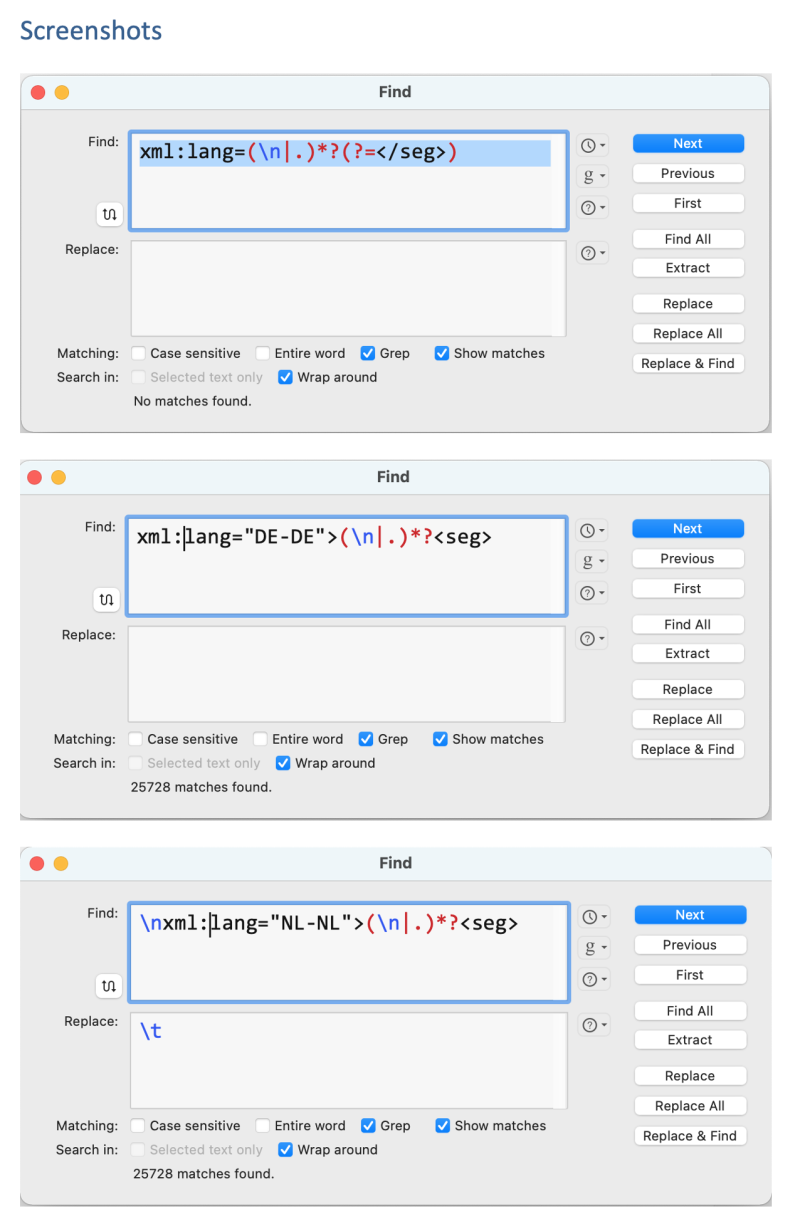
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | Zap them, these Gremlins! | Oct 14, 2022 |
Samuel Murray wrote:
The gremlins that my script removes are:
- [\x00-\x08]|\x0B|\x0C|[\x0E-\x1F] (characters that are not valid XML)
Thank you Samuel! Your selection of ranges works! In BBEdit this becomes:

I use it when I get this message:

- Any entity that's not LT, GT, AMP, APOS or QUOT
Would you mind sharing this syntax too? Thank you in advance!
EDIT: I had to add the last two items:
[\x{00}-\x{08}]|\x{0B}|\x{0C}|[\x{0E}-\x{1F}]|\x{F0B7}|\x{F0F0}
[Edited at 2022-10-14 08:39 GMT]
| | |
|
|
|
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | How to deal with new lines in segments? | Oct 14, 2022 |
Stepan Konev wrote:
If I had to do this task, I would use a text editor that supports regex (similar to Notepad++, for MacOS).
Replace them with a unique sign?
[Edited at 2022-10-14 12:35 GMT]
| | | |
Stepan Konev
Russian Federation
Local time: 18:15
English to Russian
Hans Lenting wrote:
Replace them with a unique sign? Err.. what lines do you mean? I don't quite understand.
| | | |
Samuel Murray
Netherlands
Local time: 16:15
Member (2006)
English to Afrikaans
+ ...
Hans Lenting wrote:
Samuel Murray wrote:
- Any entity that's not LT, GT, AMP, APOS or QUOT
Would you mind sharing this syntax too?
Well, since this is in a script, I don't have to use regex, remember. But maybe you can figure out a regular expression for it.
What I do, is I replace this:
&
with this:
SOMETHINGUNIQUE
throughout the file.
Then I replace this:
SOMETHINGUNIQUElt;
with this:
<
(and do the same for gt, amp, apos and quot)
Then I'm supposed to replace this:
SOMETHINGUNIQUE#
with this:
&#
but I forgot... so I would have to update my script.
And finally I replace this:
SOMETHINGUNIQUE
with this:
[entity!] &
So the reason for this is because TMX may only contain only those five character entities, as well as numbered entities.
[Edited at 2022-10-14 16:52 GMT]
| | | |
| Pages in topic: [1 2 3] > |








